本文介绍了直线段、圆弧、多边形扫描转换算法。使用 Javascript 实现多边形扫描算法。
直线段的的扫描转换算法
记得在上大学的时候,刚开始学单片机。老爸让我在液晶屏上实现画出一次方程直线的功能,当时捣鼓了一上午才搞定一条歪歪扭扭的线。这几年时间过去,又在看如何画直线,果然是轮回。
主要有三种方式 数值微分(DDA)法、中点画线法、布雷森汉姆(Bresenham)算法
DDA算法
求出直线斜率 k。当 |k| <= 1 时,x每递增1时,y递增k。当 |k| > 1 时,y 每增加1,x 增加 1 / k。这样才能保证点是连续的。
在这个算法中,y 和 k 必须用浮点数表示,而且每一步都要对 y 进行四舍五入取整,效率不高。因为是对每个像素进行处理,所以在图形学中效率非常重要,后面也会有对浮点数以及乘除的优化。
当 |k| <= 1 时,伪代码如下
1 | void DDALine(int x0, int y0, int x1, int y1, int color) |
中点画线法
通过观察下图可以看到,假如当前点为 P,则下一个像素点有两种情况,P1和P2。
M点为P1,P2中点,Q点为理想直线上的点。当 M 在 Q 下方,P2 应为下一个像素点,当 M 在 Q 上方,P1 应为下一个像素点。所以可以通过比较F(Mx, My) 和 0 的大小,可以确定下个像素点位置。
d = F(M) = F(Px + 1, Py + 0.5) = a(Px + 1) + b(Py + 0.5) + c;
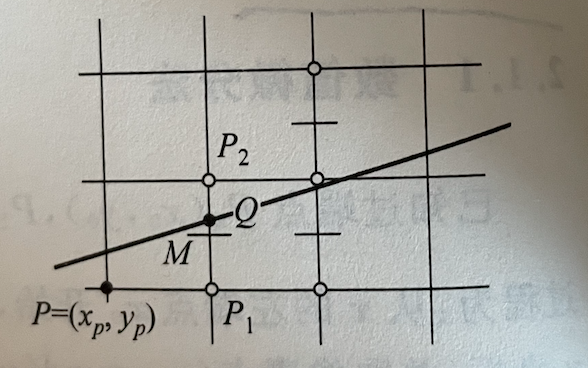
对于过 (x0, y0)(x1, y1) 两点的直线L来说,采用方程 F(x, y) = ax+ by + c = 0表示。其中 a = y0 - y1, b = x1 - x0, c = x0y1 - x1y0;
利用此方程可以画出直线,但是这种方式需要进行 4 个加法和两个乘法。事实上,d 是 Px, Py的线性函数,所以可以使用增量计算的方法优化。
若 d >= 0,则取正右方像素 P1,那么判断下一个像素位置就是d1 = F(Px + 2, Py + 0.5) = d + a;,增量为 a.
若 d < 0,则取右上方像素P2,那么判断下一个像素位置就是 d1 = F(Px + 2, Py + 1.5) = d + a + b;增量为 a + b
设从点(x0, y0)开始画线,d的初值为d0 = F(x0 + 1, y0 + 0.5) = F(x0, y0) + a + 0.5b = a + 0.5b
由于使用的只是 d 的符号,而 d 的增量都是整数,只有初始值包含小数,所以用 2d 代替 d 来摆脱浮点运算。优化过后的伪代码如下:
1 | void Midpoint Line(int x0, int y0, int x1, int y1, int color) |
Bresenham
类似于中点画线法,通过偏移量d与0.5的比较来确定像素点所在的位置,其中d1 = d0 + k;
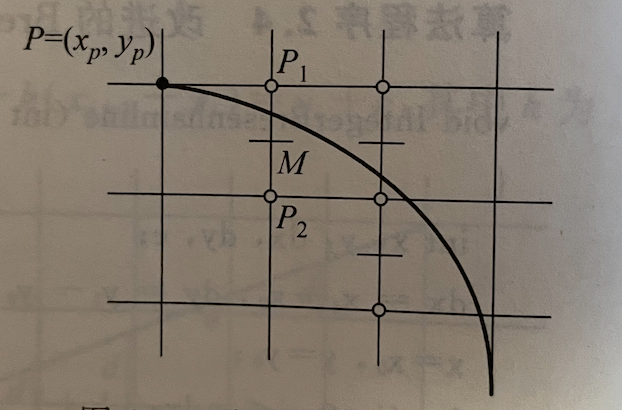
圆弧的的扫描转换算法
圆有四条对称轴,所以已知圆弧上一点(x, y),可以得到其关于4条对称轴的其他 7 个点,这种性质被称为八对称性。因此,只要扫描转换 1/8 圆弧,就可以用八对称性求出整个圆的像素集.具体算法也是类似于中点画线法,只不过函数方程变为圆。
多边形的的扫描转换算法
在计算机图形学中,多边形有顶点和点阵两种表现方式。
顶点表示直观,几何意义强,占内存少,易于进行几何变换。但不利于着色。
点阵表示丢失了许多几何信息,但便于帧缓冲器表示图形。光栅图形学的本质问题是把多边形的顶点表示转换为点阵表示,这种转换被称为多边形的扫描转换。其中有两种方法,扫描线算法和边界标志算法,下方会用 javascript 在 canvas 中实现扫描线算法。
扫描线算法
通过计算扫描线与多边形的相交区间,再用要求的颜色显示这区间的像素,以完成填充工作。区间的端点通过计算扫描线与多边形的边界线交点获得。
对于一条扫描线,主要分为下面四个步骤:
- 求交。计算扫描线与多边形各边的交点
- 排序。把所有交点按 x 值的递增顺序排序
- 配对。将1和2,3和4等等配对
- 填色。相交区间内的像素置为多边形的颜色
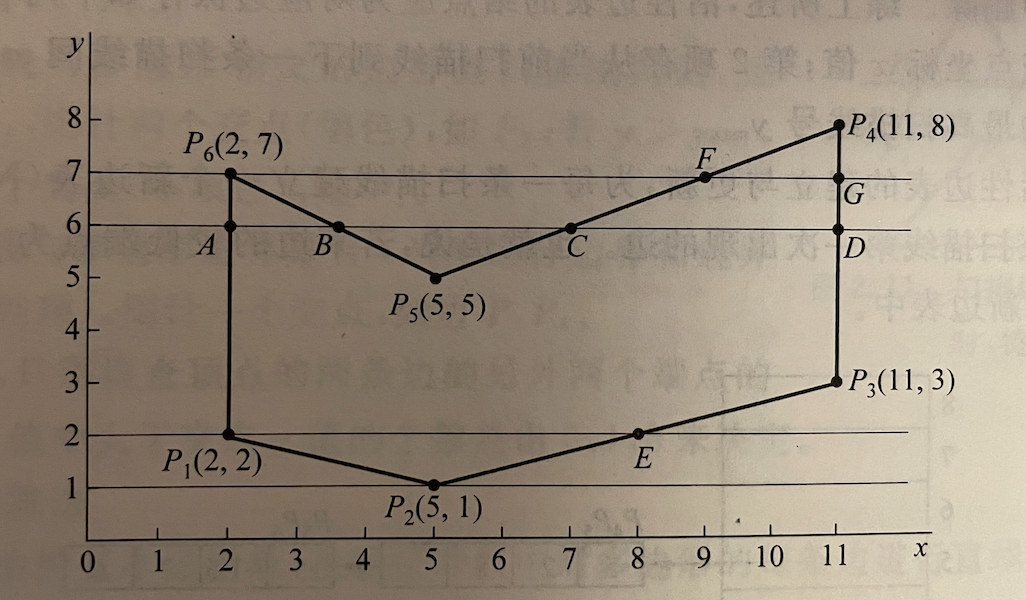
由于反复求交运算效率低下,为了优化这个问题,将引入两个概念AET和NET。
将与当前扫描线相交的边称为活性边(AET)。如果某边的较低端点为ymin,则改边就放在扫描线 ymin 的新边表(NET)中。边在 AET 和 NET 中存储使用单链表的形式。每个节点包含三个信息,1、存当前扫描线与边的交点坐标x值,2、从当前扫描线到下一条扫描线间x的增量 dx;3、存该边所交的最高扫描线号ymax。
有了NET之后,就可以通过 NET 来维护 AET,如果当前扫描线在 NET中 有值时,就加入到 AET中,每次扫描线加一,就在原来x的基础上增加dx。当扫描线号大于 ymax时,将其从AET中删除。伪代码如下
1 | void polyfill(polygon, color) |
使用 javascript 实现此算法:
1 |
|
结果如下: